Web-версия учебного курса "Основы математической статистики"
Раздел 6. Метод главных компонент
Часто результат
конкретного эксперимента выражается не одним числом, а целым
набором чисел, например, при изучении радиального распределения параметров плазмы естественно поставить вопрос о влиянии условий разряда на распределение заселенностей или температуры. Эти распределения находят отражение в наборе экспериментальных зависимостей : яркостей В(xj) или оптических толщин τ(xj), измеренных
в различных точках xj
и полученных в определенных условиях. Поскольку каждый отсчет
В(xj) определяется
с некоторой случайной погрешностью, то решение вопроса о том,
различаются ли распределения В(x), полученные для различных участков
спектра или в различных условиях разряда, может быть затруднено.
Особенно сложной становится задача классификации наблюдений,
т.е. разбиение результатов на статистически различимые группы
при большом количестве проделанных экспериментов.
Ниже прилагается рецепт решения этой задачи,
основанный на известном в математической
статистике "методе главных компонент" [10, 11].
Представим результат
k-того эксперимента в виде набора
m чисел yk1,
yk2, ..., ykj, ..., ykm; k = 1, 2, ..., p, где p - полное число проделанных экспериментов; j = 1, 2 ..., m, где m - число отсчетов, полученных в одном эксперименте.
Например, ykj - это яркость поверхности источника в точке, отстоящей на расстоянии хj от оси разряда, полученная в k-том эксперименте. (Будем считать, что во всех экспериментах яркость измеряется для одного и того же набора точек хj).
В общем случае
применения метода главных компонент результат одного
эксперимента называют "объектом", а отсчеты в одной экспериментальной
точке "признаком", поскольку метод применяется не только к анализу
массивов чисел одной размерности и одного физического смысла,
но и к наборам различных характеристик объекта.
Например, в биологии объектом может быть конкретное животное,
а признаками - его вес, длина тела, температура, частота пульса и
т.д., но при этом все характеристики должны быть выражены в
относительных единицах (т.е. как отношение к некоторому значению,
выбранному для данного признака за единицу,
сам этот выбор не принципиален).
Погрешность отсчетов в данной серии из
p экспериментов будем
характеризовать ковариационной матрицей
D погрешностей измерения y. Эту матрицу можно построить, проделав p экспериментов для одних и тех же условий. Тогда элементы матрицы вычисляются по формуле (4.12)
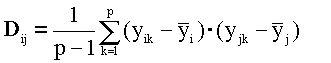
Здесь:
i и j - номера экспериментальных точек, k - номера
повторных изменений. 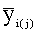 - средние по к измерениям в i-той ( j-той) точке. - средние по к измерениям в i-той ( j-той) точке.
Проделаем теперь N
экспериментов в различных условиях (получим N объектов).
Многообразие
распределений y(х),
полученных во всех N
экспериментах при различных условиях, характеризуется свойствами
ковариационной матрицы всего массива данных, где элементы матрицы определяются по формуле:
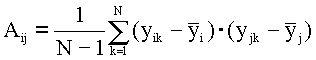 (6.1)
(6.1)
Отличие от ( 4.12) состоит в том, что здесь индекс k нумерует опыты, проведенные при различных условиях, влияние которых на вид y (х) мы хотим выявить; матрица D вычисляется по распределениям y(х), полученным при постоянных условиях, т.е. ее элементы отражают воспроизводимость результатов и корреляцию между погрешностями измерений в i-той и j -той точках х.
Результаты каждого эксперимента,
т.е. набор yk1, yk2, ..., ykj,
..., ykm можно представить
точкой в m-мерном пространстве.
Вследствие наличия случайной погрешности
в измерении каждая точка на самом деле "размывается"
в некоторую область в том же пространстве. Если две "точки"
расположены ближе, чем размер этой области размытия, то, очевидно,
результаты таких экспериментов статистически неразличим.
Если в каких-то направлениях размеры "размытия" превосходят
полные размеры области возможных значений
" y", то эти направления,
очевидно, "не информативны", т, е, в этих направлениях результаты
различных экспериментов вообще не различаются
(на рис. 6.1 данная
ситуация иллюстрируется для простейшего случая m = 2).

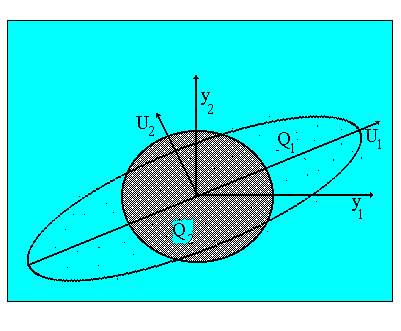
Рис.6.1 Пояснение к методу
главных компонент. y1, y2 - измеряемые величины. U1, U2 - главные направления, в данном случае U2 - неинформативное направление.
Области
всех возможных значений y(Q1)
определяются матрицей A, а область "размытия"(Q2) - матрицей
D. Матрица
AD-1называется информационной матрицей.
Она определяет область возможных значений в
m-мерном информационном
пространстве безразмерных величин
(каждое yij
измеряется в единицах своей погрешности).
Если хоть в каком-нибудь направлении размер этой области больше 1,
значит в нашем ансамбле распределений
y(x) есть статистически различимые.
Найдем все собственные значения λw матрицы AD-1 (w = 1, 2, ..., q),
которые больше 1,
и соответствующие собственные
вектора Uw.
Количество q этих собственных значений показывает, каким числом независимых параметров характеризуется индивидуальность каждого конкретного результата эксперимента. Дальнейшее применение метода целесообразно, если q существенно меньше m.
Величина 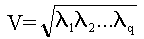 характеризует "информационный объем" эксперимента, т.е. показывает, сколько статистических различных классов есть в нашем ансамбле распределений. характеризует "информационный объем" эксперимента, т.е. показывает, сколько статистических различных классов есть в нашем ансамбле распределений.
Для того, чтобы разбить ансамбль на эти классы,
надо найти проекции С kw
экспериментальных "точек" yk
на собственные вектора Uw:
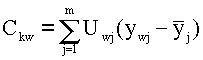 (6.2)
(6.2)
здесь Uwj
- компоненты w-того собственного
вектора матрицы AD-1 (w=1, 2, .., q; j = 1, 2, .., m).
Собственный вектор,
отвечающий наибольшему собственному значению,
называют "главным направлением" - проекции на него для различных
объектов сильнее всего отличаются.
"Погрешность"
коэффициентов оценивается по формуле :
Sw2=UwTDUw
(6.3)
К одному классу мы отнесем те распределения y(х), у которых все q коэффициентов Сw неразличимы в пределах своих погрешностей.
Метод может дать полезную информацию и в том случае, если матрица D не известна (повторные измерения при неизменных условиях не проводились). Экспериментатор может, исходя из априорных соображений, классифицировать наблюдения по проекциям только на один первый вектор (напомним, что это комбинация признаков х, по которым зависимости y(х) более всего отличаются, т.к. нахождение собственных векторов означает приведение матрицы к диагональному виду, при этом собственное значение характеризует дисперсию, т.е. разброс экспериментальных "точек" вдоль соответствующего направления). В более сложных случаях можно использовать два и более главных направлений, если есть априорная уверенность в их значимости.
Метод может быть применен и для классификации
изображений. Распределение яркостей в поле изображений можно
"вытянуть" в одномерные массивы, нумеруя в каком либо определенном
порядке элементы поля изображений. После нахождения значимых векторов
их можно вновь представить в двумерном виде. Изготовив транспарант
с пропусканием пропорциональным значению компонент вектора получают
маски (так называемые маски Карунена - Лоэва ), наложив которые на самосветящиеся
или пропускающие свет объекты или их изображения и измерив прошедший
световой поток, сразу получают проекции изображений на эти вектора.
Метод используется для быстрого распознавания детерминированных
изображений в системах технического зрения, при этом часто достаточно
не воспроизводить точно компоненты вектора, а использовать бинарные
маски. Например, сначала наложить маску, полностью пропускающую свет
в точках, где компоненты вектора положительны, потом - пропускающую
свет в точках, где компоненты вектора отрицательны и вычислить разность
отсчетов. Эту же операцию может выполнить за один такт матрица
фотодиодов, если подключить их соответствующим образом и сфокусировать
на нее анализируемые изображения. (Метод не инвариантен к сдвигу,
повороту и изменению масштаба изображения; в тех случаях, когда
заранее известно, какие изображения следует отнести к одному классу,
применяется совершенно другой принцип распознавания -
обучаемая нейросеть [12]).
Изложенный
метод не только помогает классифицировать результаты,
но иногда облегчает их дальнейшую обработку.
|
 |
|