Модели нейронных сетей
Модель Маккалоха
Модель Розенблата
Модель Хопфилда
Модель сети с обратным распространением
Модель Маккалоха
Теоретические основы нейроматематики были заложены в начале 40-х годов. В 1943 году У. Маккалох и его ученик У. Питтс сформулировали основные положения теории деятельности головного мозга.- Ими были получены следующие результаты:
- разработана модель нейрона как простейшего процессорного элемента, выполняющего вычисление переходной функции от скалярного произведения вектора входных сигналов и вектора весовых коэффициентов;
- предложена конструкция сети таких элементов для выполнения логических и арифметических операций;
- сделано основополагающее предположение о том, что такая сеть способна обучаться, распознавать образы, обобщать полученную информацию.
Несмотря на то, что за прошедшие годы нейроматематика ушла далеко вперед, многие утверждения Макклоха остаются актуальными и поныне. В частности, при большом разнообразии моделей нейронов принцип их действия, заложенный Макклохом и Питтсом, остается неизменным. Недостатком данной модели является сама модель нейрона "пороговой" вид переходной функции. В формализме У. Маккалоха и У. Питтса нейроны имеют состояния 0, 1 и пороговую логику перехода из состояния в состояние. Каждый нейрон в сети определяет взвешенную сумму состояний всех других нейронов и сравнивает ее с порогом, чтобы определить свое собственное состояние.
Пороговый вид функции не предоставляет нейронной сети достаточную гибкость при обучении и настройке на заданную задачу. Если значение вычисленного скалярного произведения, даже незначительно, не достигает до заданного порога, то выходной сигнал не формируется вовсе и нейрон "не срабатывает". Это значит, что теряется интенсивность выходного сигнала (аксона) данного нейрона и, следовательно, формируется невысокое значение уровня на взвешенных входах в следующем слое нейронов.
Модель Розенблата
Серьезное развитие нейрокибернетика получила в работах американского нейрофизиолога Френсиса Розенблата (Корнелльский университет). В 1958 году он предложил свою модель нейронной сети. Розенблат ввел в модель Маккаллока и Питтса способность связей к модификации, что сделало ее обучаемой. Эта модель была названа перцептроном. Первоначально перцептрон представлял собой однослойную структуру с жесткой пороговой функцией процессорного элемента и бинарными или многозначными входами. Первые перцептроны были способны распознавать некоторые буквы латинского алфавита. Впоследствии модель перцептрона была значительно усовершенствована.
Перцептрон применялся для задачи автоматической классификации, которая в общем случае состоит в разделении пространства признаков между заданным количеством классов. В двухмерном случае требуется провести линию на плоскости, отделяющую одну область от другой. Перцептрон способен делить пространство только прямыми линиями (плоскостями).
- Алгоритм обучения перцептрона выглядит следующим образом:
- системе предъявляется эталонный образ;
- если выходы системы срабатывают правильно, весовые коэффициенты связей не изменяются;
- если выходы срабатывают неправильно, весовым коэффициентам дается небольшое приращение в сторону повышения качества распознавания.
Серьезным недостатком перцептрона является то, что не всегда существует такая комбинация весовых коэффициентов, при которой имеющееся множество образов будет распознаваться данным перцептроном. Причина этого недостатка состоит в том, что лишь небольшое количество задач предполагает, что линия, разделяющая эталоны, будет прямой. Обычно это достаточно сложная кривая, замкнутая или разомкнутая. Если учесть, что однослойный перцептрон реализует только линейную разделяющую поверхность, применение его там, где требуется нелинейная, приводит к неверному распознаванию (эта проблема называется линейной неразделимостью пространства признаков). Выходом из этого положения является использование многослойного перцептрона, способного строить ломаную границу между распознаваемыми образами.
Описанная проблема не является единственной трудностью, возникающей при работе с перцептронами - также слабо формализовани метод обучения перцептрона.
Перцептрон поставил ряд вопросов, работа над решением которых привела к созданию более "разумных" нейронных сетей и разработке методов, нашедших применение не только в нейрокибернетике (например, метод группового учета аргументов, применяемый для идентификации математических моделей).
Модель Хопфилда
В 70-е годы интерес к нейронным сетям значительно упал, однако работы по их исследованию продолжались. Был предложен ряд интересных разработок, таких, например, как когнитрон, и т.п.), позволяющих распознавать образы независимо от поворота и изменения масштаба изображения.
Автором когнитрона является японский ученый И. Фукушима.
Новый виток быстрого развития моделей нейронных сетей, который начался лет 15 тому назад, связан с работами Амари, Андерсона, Карпентера, Кохонена и других, и в особенности, Хопфилда, а также под влиянием обещающих успехов оптических технологий и зрелой фазы развития СБИС для реализации новых архитектур.
Начало современному математическому моделированию нейронных вычислений было положено работами Хопфилда в 1982 году, в которых была сформулирована математическая модель ассоциативной памяти на нейронной сети.
Показано, что для однослойной нейронной сети со связями типа "все на всех" характерна сходимость к одной из конечного множества равновесных точек, которые являются локальными минимумами функции энергии, содержащей в себе всю структуру взаимосвязей в сети. Понимание такой динамики в нейронной сети было и у других исследователей. Однако, Хопфилд и Тэнк показали как конструировать функцию энергии для конкретной оптимизационной задачи и как использовать ее для отображения задачи в нейронную сеть. Этот подход получил развитие и для решения других комбинаторных оптимизационных задач. Привлекательность подхода Хопфилда состоит в том, что нейронная сеть для конкретной задачи может быть запрограммирована без обучающих итераций. Веса связей вычисляются на основании вида функции энергии, сконструированной для этой задачи.
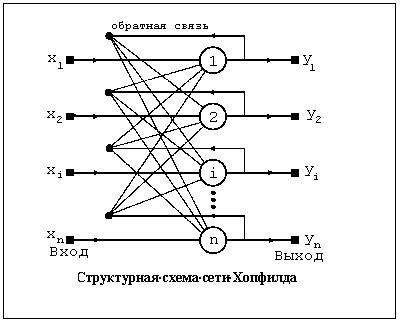
Развитием модели Хопфилда для решения комбинаторных оптимизационных задач и задач искусственного интеллекта является машина Больцмана, предложенная и исследованная Джефери Е. Хинтоном и Р. Земелом. В ней, как и в других моделях, нейрон имеет состояния 1, 0 и связь между нейронами обладает весом. Каждое состояние сети характеризуется определенным значением функции консенсуса (аналог функции энергии). Максимум функции консенсуса соответствует оптимальному решению задачи.
Модель сети с обратным распространением
Способом обратного распространения (back propogation) называется способ обучения многослойных нейронных сетей (НС).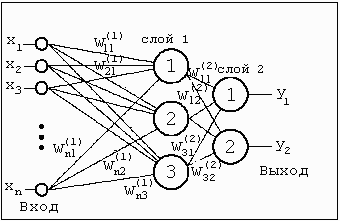 Многослойная нейронная сеть
Многослойная нейронная сеть
В таких НС связи между собой имеют только соседние слои, при этом каждый нейрон предыдущего слоя связан со всеми нейронами последующего слоя. Нейроны обычно имеют сигмоидальную функцию возбуждения. Первый слой нейронов называется входным и содержит число нейронов соответствующее распознаваемому образу. Последний слой нейронов называется выходным и содержит столько нейронов, сколько классов образов распознается. Между входным и выходным слоями располагается один или более скрытых (теневых) слоев. Определение числа скрытых слоев и числа нейронов в каждом слое для конкретной задачи является неформальной задачей. Принцип обучения такой нейронной сети базируется на вычислении отклонений значений сигналов на выходных процессорных элементах от эталонных и обратном "прогоне" этих отклонений до породивших их элементов с целью коррекции ошибки.
Еще в 1974 году Поль Дж. Вербос изобрел значительно более эффективную процедуру для вычисления величины, называемой производной ошибки по весу, когда работал над своей докторской диссертацией в Гарвардском университете. Процедура, известная теперь как алгоритм обратного распространения, стала одним из наиболее важных инструментов в обучении нейронных сетей. Однако этому алгоритму свойственны и недостатки, главный из которых - отсутствие сколько-нибудь приемлемых оценок времени обучения. Понимание, что сеть в конце концов обучится, мало утешает, если на это могут уйти годы. Тем не менее, алгоритм обратного распространения имеет широчайшее применение.